Knowmak Classification
Context
-
The "Knowmak Classification" scenario is designed to explore abstracts from Knowmak projects and provide insights into semantic evolution and classification of topics. The user is prompted to input a dataset title, select indicators related to knowledge production and technology, and choose a grouping parameter (country, region, or topic). It serves as a comprehensive tool for analyzing and classifying knowledge-related indicators within the Knowmak framework.
Steps
-
Upon logging in, start a new project and proceed to import the "Knowmak Classification" scenario. Next, configure the scenario by filling in the necessary inputs:
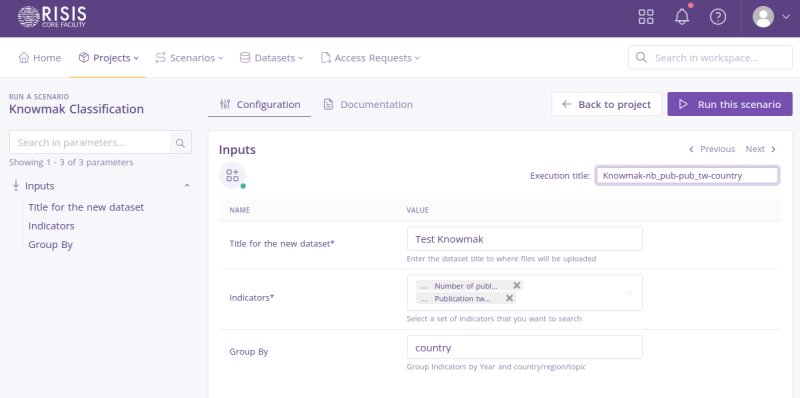
- Execution title: Enter an execution title to categorize each scenario configuration execution. This field is optional.
- Title for the new dataset: Enter a name for the new dataset. For this example, we selected 'Test Knowmak'.
- Indicators: Choose from the list the indicators you're interrested in. For this example, we selected the indecators: 'Number of publications' and 'Publication tweeted'.
- Group By: Group Indicators by Year and country/region/topic. You can switch between possibles values (see bellow).

-
When all the required fields are filled, you can click the button in the top right ‘Run this scenario’.
-
After the scenario execution is finished, check in the Outputs of the project for the new file produced:
Knowmak Classification, which contains two tsv files:number-of-publications-groupby-country.tsvandpublication-tweeted-groupby-country.tsv.