Introduction
In the present page, you will find a description of the basic procedures to use RCF web application for the general user.
What is RCF?
The objective of the Risis Core Facility is to provide a ground-breaking infrastructure for Science, Technology, and Innovation (STI) studies. In order to get a functional Risis Core Facility (RCF), the infrastructure must provide a unique entry point online, with which RISIS users can access a monitored and secured workspace. This workspace will be designed to provide services to users interested in jointly exploiting different RISIS datasets and various Linked Open Data resources with the goal to explore, retrieve and visualize results of data analysis for their research purposes.
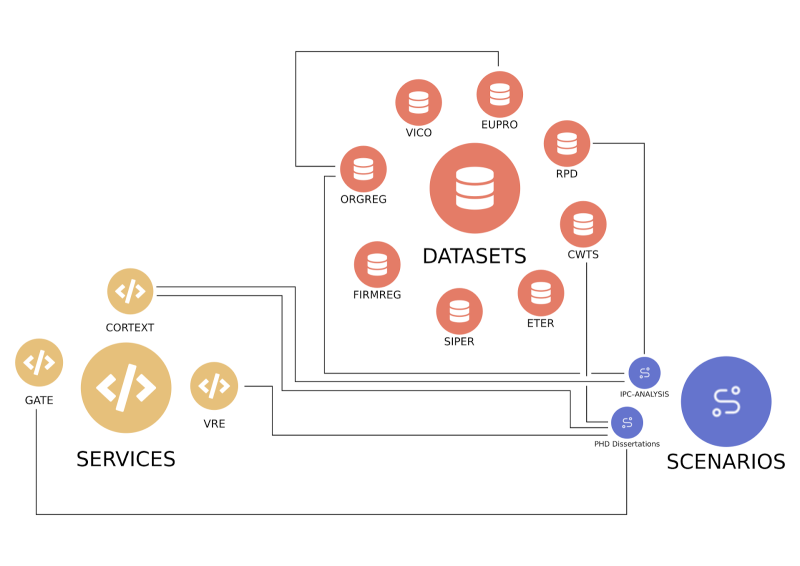
From the user’s point of view, he/she will be interacting with the web application Risis Workspaces (also known as Rimow). This application will allow access to RISIS datastore (holding RCF locally stored datasets), upload of datasets, create and manage projects and launch a variety of scenarios (data extraction, analysis via Risis services, and report generation). It also provides the interface to navigate the scenarios results and access external tools provided with results data. In the following, you will find a detailed description of those concepts, and a set of procedures on the usage of RCF.
MAIN RCF CONCEPTS
Dataset
A dataset is a collection of files and metadata stored in the RCF Datastore. A dataset is a described, versioned, and citable resource (with its DOI identifier), that ensures that the data linked to a particular scenario and, later on, publication, is properly identified and does not change over time. In order to give a scenario some data to handle, datasets have to be imported into projects. Dataset files can then be used as inputs for running scenarios in projects.
Bellow, you can find the main Risis datasets. For more informations, check https://rcf.risis.io/access-request/datasets.
| Datasets | Description |
|---|---|
| CHEETAH | It is a database featuring geographical, industry and accounting information on three cohorts of mid-sized firms that experienced fast growth during the periods 2008-2011, 2009-2012 and 2010-2013. |
| CIB / CinnoB | Corporate Invention and Innovation Boards is a database about largest R&D performers and their subsidiaries worldwide, providing patenting and other indicators. |
| CWTS Publication Database | It is a full copy of Web of Science (WoS) dedicated to bibliometric analyses, with additional information e.g. on standardised organisation names and other enhancements. |
| EUPRO | It is a unique dataset providing systematic and standardized information on R&D projects of different European R&D policy programmes. |
| RISIS Patent | It offers an enriched and cleaned version of the PATSTAT database, with a focus on standardised organisation names and geolocalisation. |
| JOREP 2.0 | It is a database on European trans-national joint R&D programmes, storing a basic set of descriptors on the programmes and agencies participating to the programmes. |
| MORE | (Mobility Survey of the Higher Education Sector) is a comprehensive empirical study of researcher mobility in Europe. |
| NANO | S&T dynamics database (Nano) collects publications and patents between 1991 and 2011 about Nano S&T. |
| PROFILE | It is a longitudinal study focusing on the situation of doctoral candidates and their postdoctoral professional careers at German universities and funding organisations. |
| RISIS-ETER | It represents an extension by additional indicators in terms of research activities of the European Tertiary Education Register database. |
| SIPER | Science and Innovation Policy Evaluations Repository (SIPER) is a rich and unique database and knowledge source of science and innovation policy evaluations worldwide. |
| VICO | It is a database comprising geographical, industry and accounting information on start-ups that received at least one venture capital investment in the period 1998-2014. |
| ESID | It is a comprehensive and authoritative source of information on social innovation projects and actors in Europe and beyond. |
| EFIL | EFIL provides data useful for characterizing research funding instruments managed by selected European Research Funding Organizations. |
| ISI-Trademark Data Collection (ISI-TM) | It provides detailed information on trademarks filed at the EUIPO and at the USPTO. |
Services
CORTEXT
CORTEXT is a platform for on-line processing of heterogeneous textual corpuses and currently it operates as a platform offering researchers different ways to enrich and analyse their corpuses. CorTexT provides text mining tools and socio-semantics analysis for corpus-level (inter-document) analysis, including data parser (txt, doc, json, ris and other proprietary format such as WoS, Scopus, Factiva,…), term extraction, generation of word2vec models, interaction networks (e.g. retweet networks), clustering, geocoding, and graph-based community detection. It also give user access to numerous data viz such as sankey “tubes”, network map, geographic map, etc.
GATE
GATE Cloud is complementary to CorTexT, as it provides numerous open-source multilingual natural language processing tools and services for text analysis, on a document-by-document basis. This includes lexical analysis, Named Entity Recognition (NER), social media analysis, entity linking with Linked Open Data (LOD) resources), and ontology-based semantic annotation via the KNOWMAK annotation service (see INDICATORS TOPICS-ONTOLOGY page). More services will be made available in the RCF as the project progresses.
D4SCIENCE
D4Science is a Hybrid Data Infrastructure serving a number of Virtual Research Environments exploited in the context of several European projects and international partnerships. D4Science will design, deploy, and operate a VRE (Virtual Research Environment) to foster interaction between RISIS-RCF and OpenAire with the view to have the RISIS project to contribute to the OSaaS (Open Science as a Service), while linking a Community Based Infrastructure in science policy and innovation studies.
OPENAIRE
It is the European Data Infrastructure for Scientific Open Access. CNR-ISTI is responsible of the OpenAIRE development and pre-production infrastructure. Specific and relevant databases and contents will be imported from the OpenAIRE infrastructure, through the implementation of a VRE by D4Science.
Scenario
A scenario is a set of tasks that produces results in an orchestrated and repeatable way. A scenario is a recipe of sorts, with ingredients being the RISIS datasets and services, and steps being the tasks and sub-tasks. A scenario’s metadata, its description, and the tasks workflow it’s made of are described in a specific format called RSML (Risis Scenario Modeling Language) and are kept in text files. The RCF’s RSML engine is able to run a Scenario by reading an RSML file, along with a set of user input parameters, given by the scenario configuration interface in RCF.
Projects
Projects are places where Datasets and Scenarios can be imported, giving users the ability to run scenarios using datasets as inputs. Results obtained after running scenarios in projects can then be found and explored on the project’s outputs page. Projects will serve as the base unit to keep the data, scenarios instances, and results regarding a particular project in a specific location.